Not to brag, but we have some amazing partnerships with industry-leading open-source vendors. You may have heard some news about Hortonworks lately, that they recently went through a “little” merger. You can read up about it just about everywhere since it’s all the buzz but take it right from the horse’s elephant’s mouth on the Hortonworks blog. We’re really excited.

This means two of the biggest names in Big Data are joining forces to bring their best-of-breed technologies together in a more impactful way. We’ll see innovation at a higher rate, and more value delivered across a wider base. What’s even better is that the core group of the originating architects and engineers who made key components in the Hadoop ecosystem went and planted their flags at Cloudera and Hortonworks early on, so it’s almost like the band is getting back together! This is The Triple Threat, or a Win-Win-Win if you ask us.

Elephant in the room
Now, Big Data is a big word.
What does it mean? Is it just Data at Rest, or can it also be Data in Motion? ETL and streaming capabilities? Core compute, fabric and distributed processing, or edge and IoT capabilities? Is this when we can start talking about Machine Learning and Data Science? Already feels like you’re drowning in a Data Lake, eh?
Ask almost anyone and they’ll say “Hadoop” but Hadoop is an ecosystem and a set of technologies to form a solution. Delve into this Hadoop ecosystem you’ll find the core technology being HDFS or the Hadoop Distributed File System, YARN is the brains of the operation, MapReduce enables massively parallel data operations, and this is just scratching the surface. You’ll quickly find things such as Knox for security, Ambari for lifecycle management, Spark, Hive, Pig, Nifi, and the list goes on. And why yes, you do end up with sudden urges to take a jaunt to your local zoo…that’s natural.
These and other technologies go into creating solutions that can power your scale-out and scale-up Data at Rest strategies, and enable processing of streams of Data in Motion at the edge and inside the data center. You’ll find these solutions masterfully integrated, supported, and delivered by Hortonworks with their Hortonworks Data Platform for handling Data at Rest workloads, and their Hortonworks Data Flow solution to provide the Data in Motion functionality that your organization needs.
Data Science 101 Workshop
Here at Fierce Software, we like to work with our partners to drive opportunity of course, but one of the most rewarding things we do is in providing our workshops. This lets us get in front of our customers and ensure that they know the technologies at hand and have plenty of time to discuss, and actually get to work with the solutions hands-on to see if it’s a right fit. We’ve run workshops all around North America, and have had a long standing cadence of delivering Ansible Tower, OpenShift Container Platform, and DevSecOps workshops, and it’s something we love to do.
Today we’d like to announce our Data Science 101 Workshop, brought to you in part by our friends over at Hortonworks!

In this workshop, we’ll start with a high-level overview of Hortonworks, a little background and history behind the folk that bring us these amazing technologies. Then we’ll dive into the Hortonworks ecosystem and explore some of the key components, detailing the ones we’ll be working with later in the hands-on portion. There’ll be some mild conjecture about Data Science concepts, and the capabilities Hortonworks can provide with their many enterprise-ready solutions. We break from the Death by Powerpoint and Q&A portion with a lunch, because we ALWAYS bring good grub for your brain AND your belly.
Then we break out the fleet of Chromebooks and get our hands dirty playing with Hortonworks Cloudbreak, Ambari, and Zeppelin as we progress through loading data into HDFS, minor administration and operation, and a few Data Science workloads with Random Forest Machine Learning models! Sounds like a lot, and a lot of fun, right?!
As much as I’d like to play the whole movie here, we’ve only got a trailer’s worth of time. I would like to take this short moment to showcase one of the key technologies we use in this Data Science 101 Workshop, Hortonworks Cloudbreak.
Flying Mile-high with Hortonworks Cloudbreak
If there’s anything I’d bet on these days is that most organizations are looking for hybrid cloud flexibility in their Data Analytic workloads. I get it, sometimes you need to scale out quickly and it’s super easy to attach a few EC2 instances for some extra compute, and the price of cold-storage solutions in the cloud is getting better and better (watch out for the egress fees though and reprovisioning times though!). Thankfully you can easily deploy, manage, and run your Hortonworks environments in AWS, Azure, Google Cloud, and even OpenStack with Hortonworks Cloudbreak.
Hortonworks Cloudbreak allows you to deploy Hortonworks clusters in just a few clicks, be that Hortonworks Data Platform to map large sets of data, or Hortonworks Data Flow to work with Nifi and Streaming Analytics Manager. Cloudbreak also allows for easy management of these clusters, and they can be deployed on the major cloud solutions out there today. This means you can run side-by-side A/B testing workloads very easily without having to architect and manually deploy the underlying infrastructure. Maybe as a Data Scientist, you want to experiment with a cluster that isn’t production, or as an infrastructure operator, you’d like to quickly template and deploy differently configured clusters for performance testing. Whatever it is you’re doing, starting with Hortonworks Cloudbreak is the best and easiest way to get going.
Deploying Hortonworks Cloudbreak
Getting up and running with Hortonworks Cloudbreak really couldn’t be easier. It’s containerized and can be easily deployed into a VM, or within a few clicks, you can deploy a Quickstart on your favorite cloud service. We typically deploy to AWS or Red Hat’s OpenStack, and even if you’re using a different cloud platform, within a few steps you should be presented with the Hortonworks CloudBreak login page…

Cloud ‘creds
Alrighty, upon login in a fresh installation of Hortonworks Cloudbreak you’ll be prompted to supply credentials to connect to a public cloud service of your choice. Since Cloudbreak works with any supported public cloud service, from any environment, you can deploy Cloudbreak on-premise on OpenStack for instance, and have it deploy clusters into AWS. You can even set up multiple credentials and different credential types to enable true hybrid-cloud data strategies.
Cloudbreak into a new Cluster
Right after setting up your first set of credentials, you’ll be sent right to the Create a Cluster page. Cloudbreak wastes no time, but when you do get this cluster built to take a moment to check out the sights.
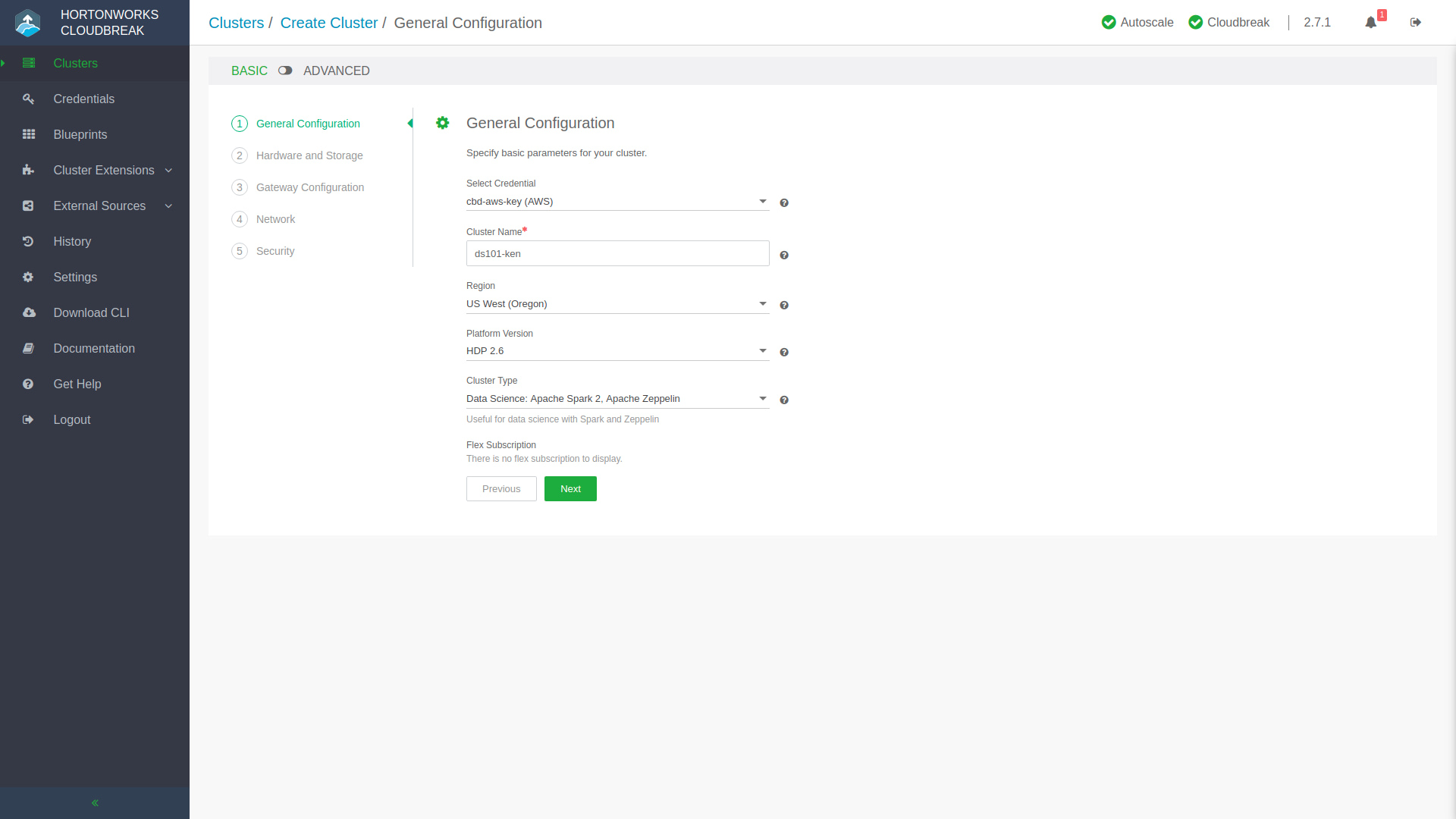
The Create a Cluster process is extremely straight-forward. Select what credentials you want to use (maybe the ones you just set up), give your cluster a name, and pick where you want its home to be. Then you’ll select what type of platform technology you’d like your cluster to be based off of, either HDP or HDF, and what kind of cluster you want. The “Cluster Type” specification is a selection of Ambari Blueprints, these Blueprints let you quickly create and distribute templated cluster structures.
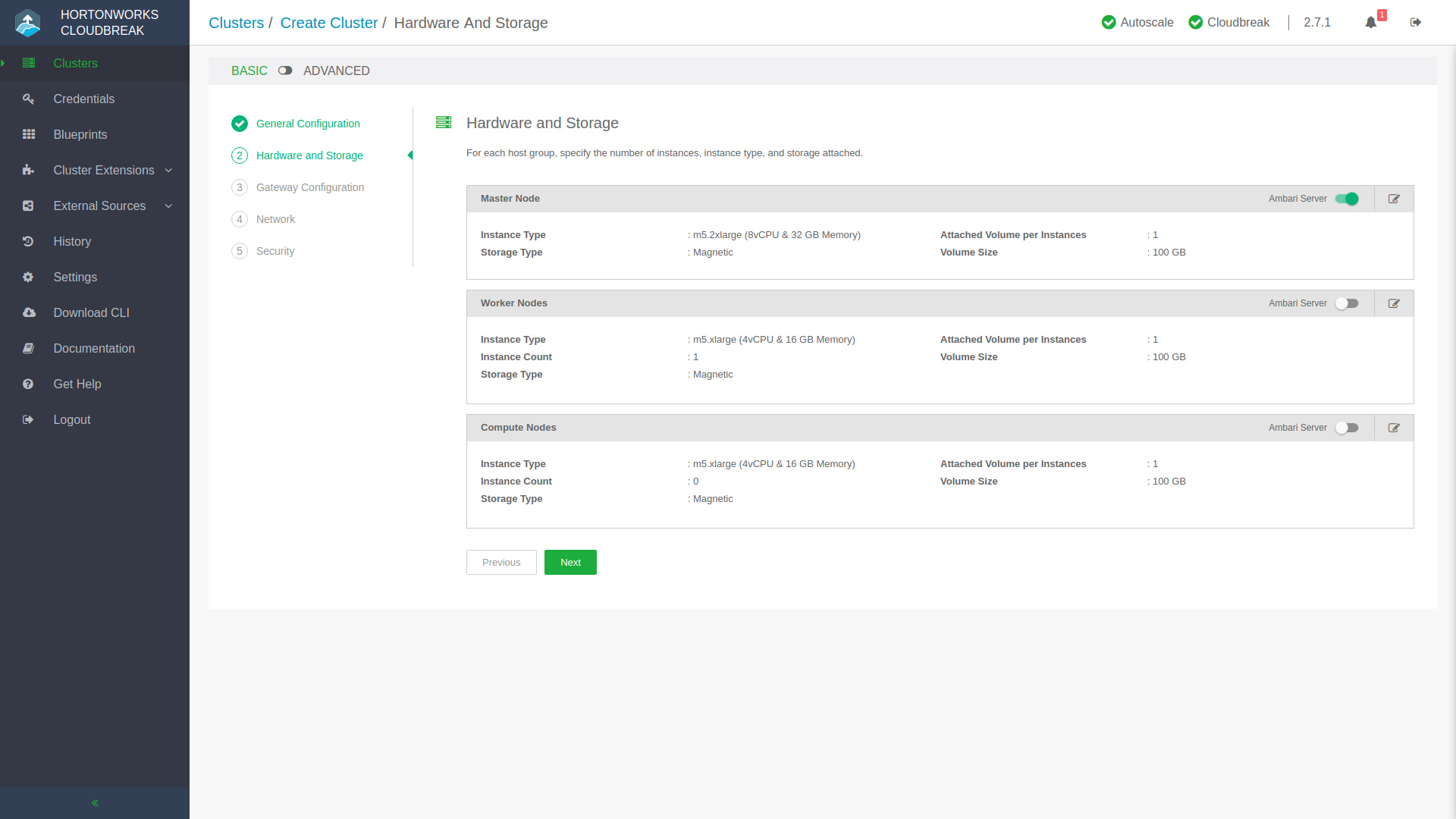
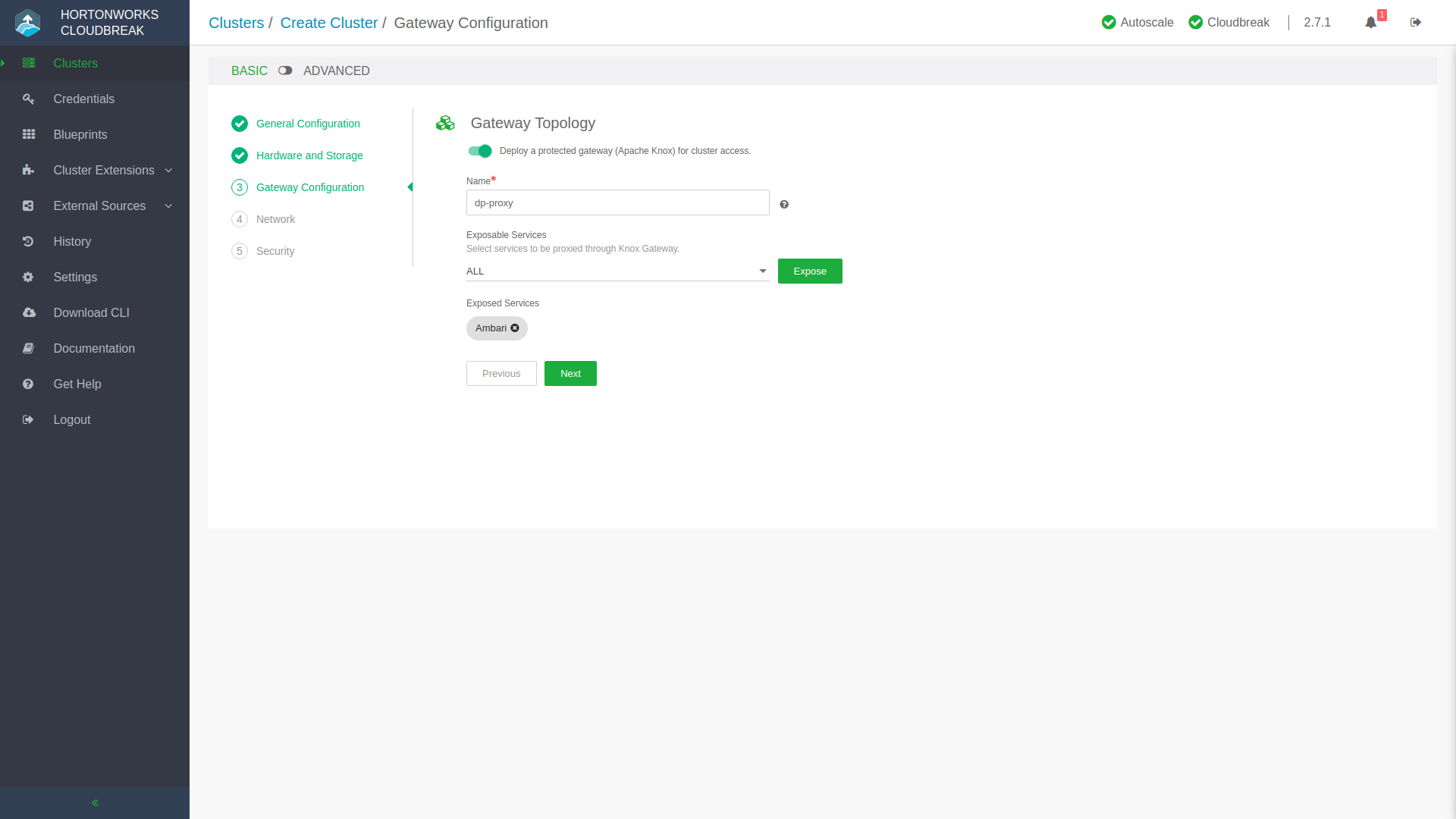
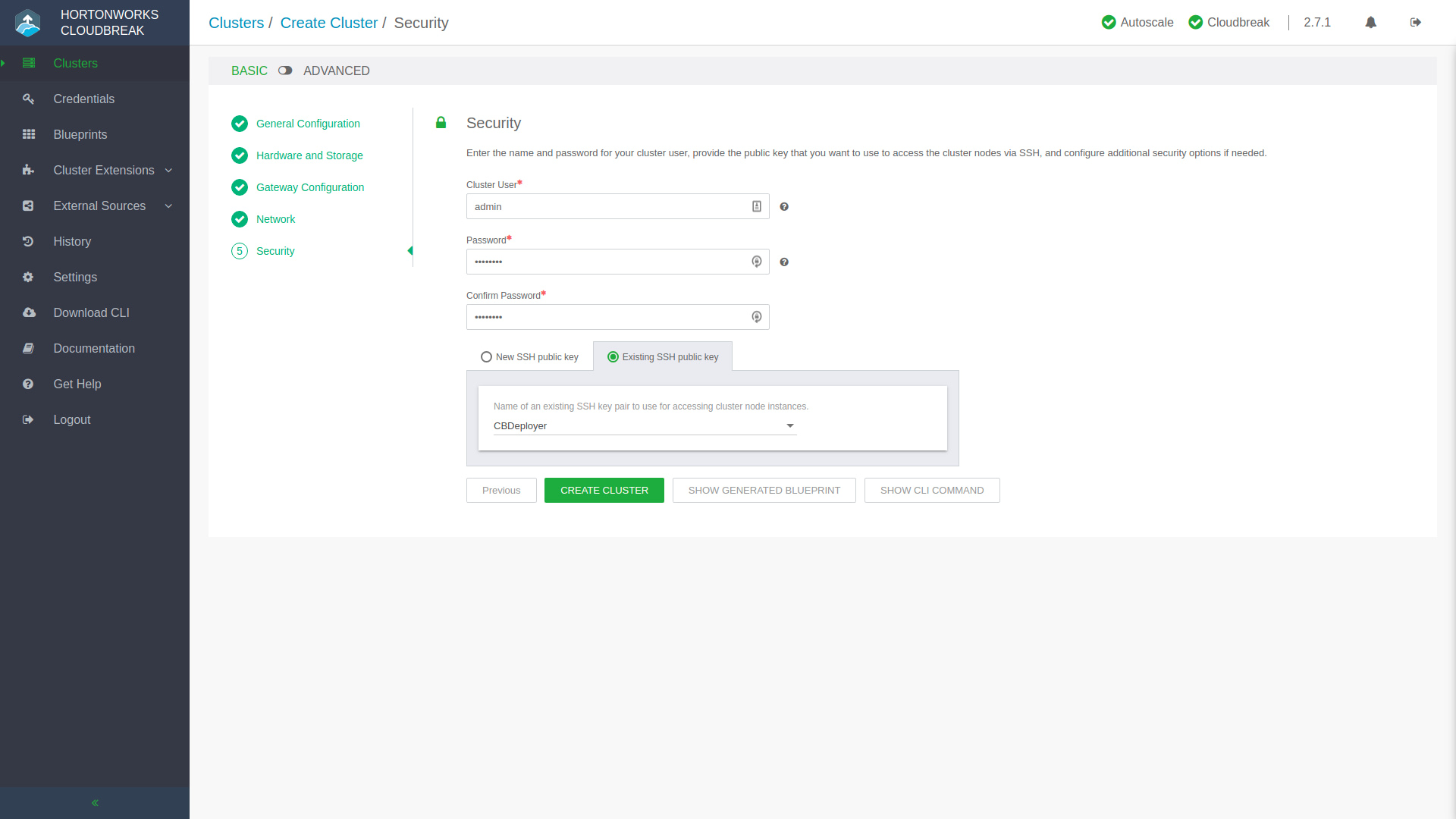
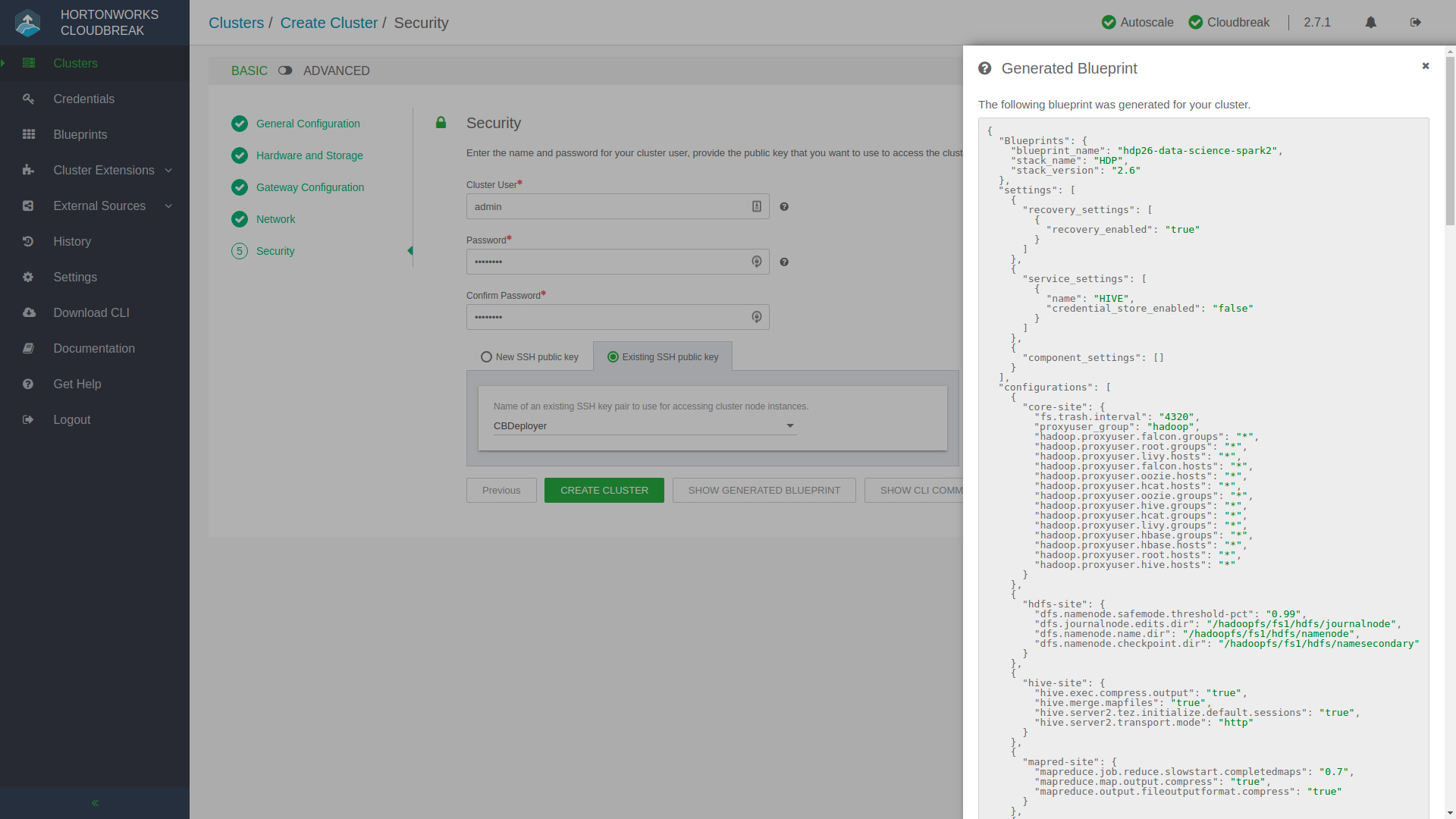
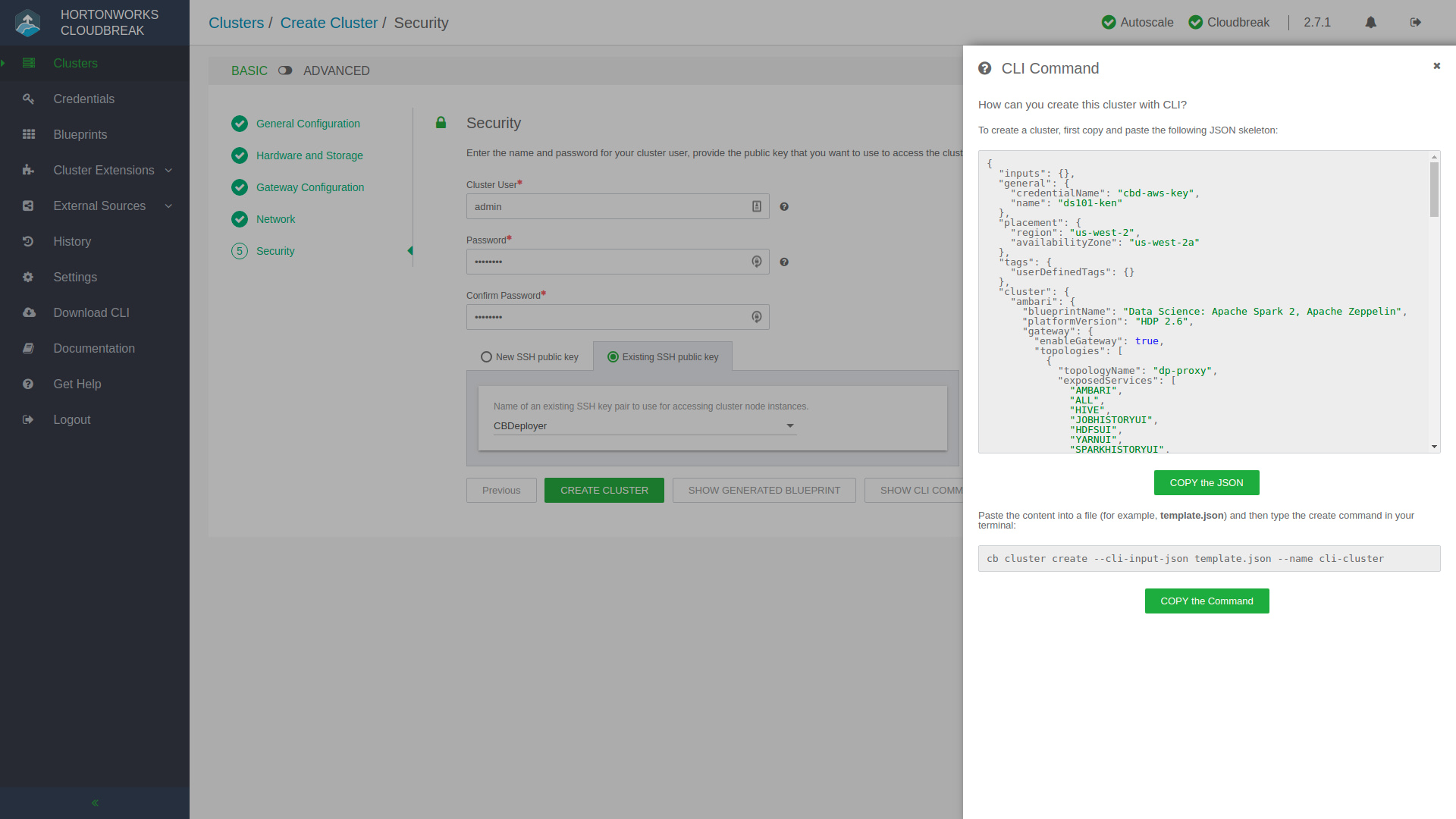
You’ll progress through a few more stages, next being Hardware and Storage where you can set the cluster node counts, and volume sizes for their data stores, amongst other infrastructure configuration. Knox is what protects the fort and acts as a secure gateway into the environment, you can quickly add exposed services in the Gateway Configuration step. Once you set up the moat and drawbridge, you’ll want to create a secret handshake and passphrase in the Security step after you’ve gone through the Network configuration. At the final stage of creating your cluster, you’ll see a few extra buttons next to that big green Create Cluster button. Show Generated Blueprint will compile the Ambari Blueprint that represents your newly configured cluster so if you’d like to quickly make modifications on a pre-packaged Blueprint and save it you can do so by creating your very own Blueprint! Maybe you’d like to include the deployment of a cluster in a DevOps CI/CD pipeline? You can click Show CLI Command and use the provided command to script and automate the deployment of this cluster, because let’s not forget that you can interact with the Hortonworks environment with Web UIs, APIs, and the CLI – oh my!
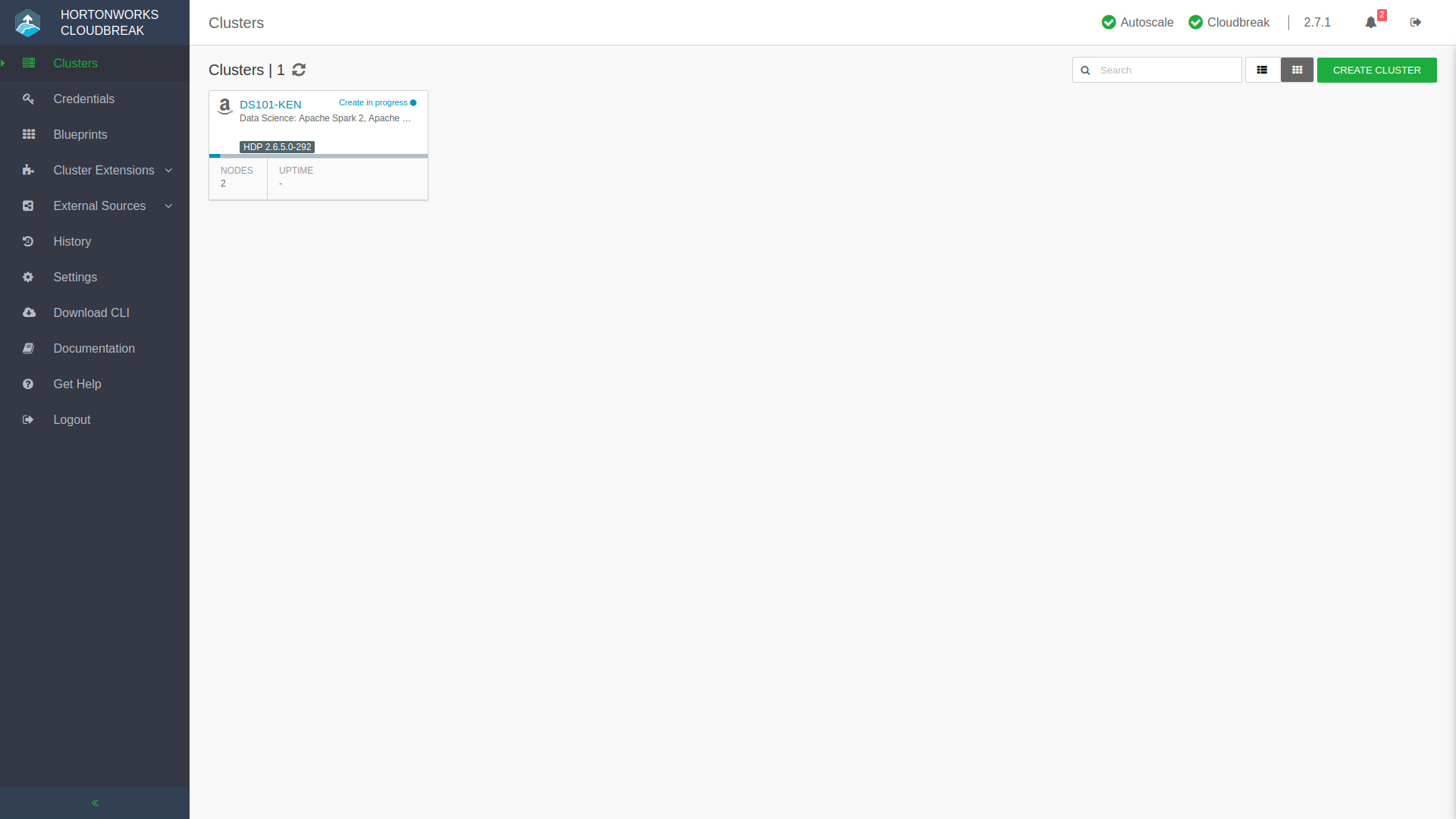
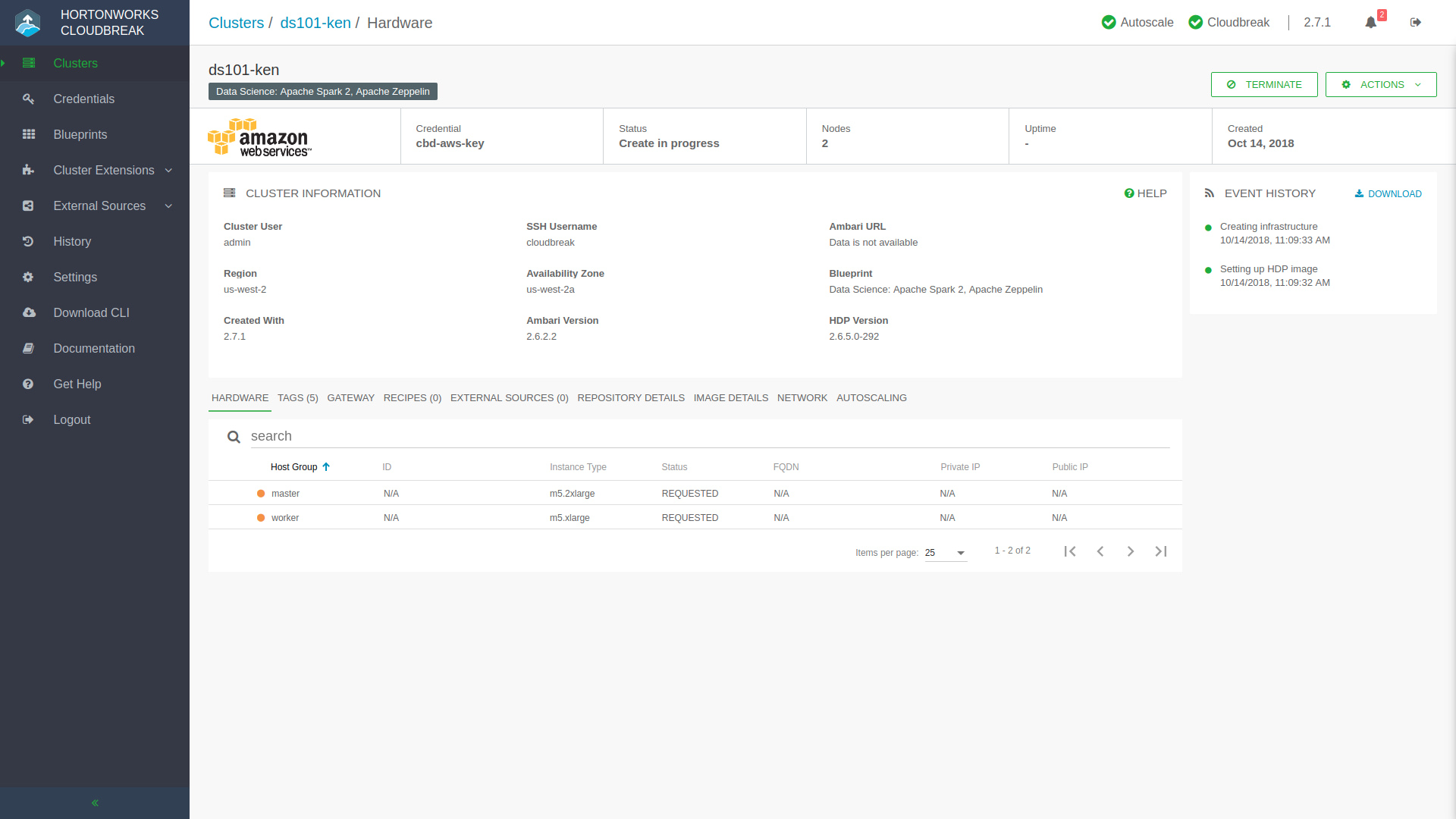
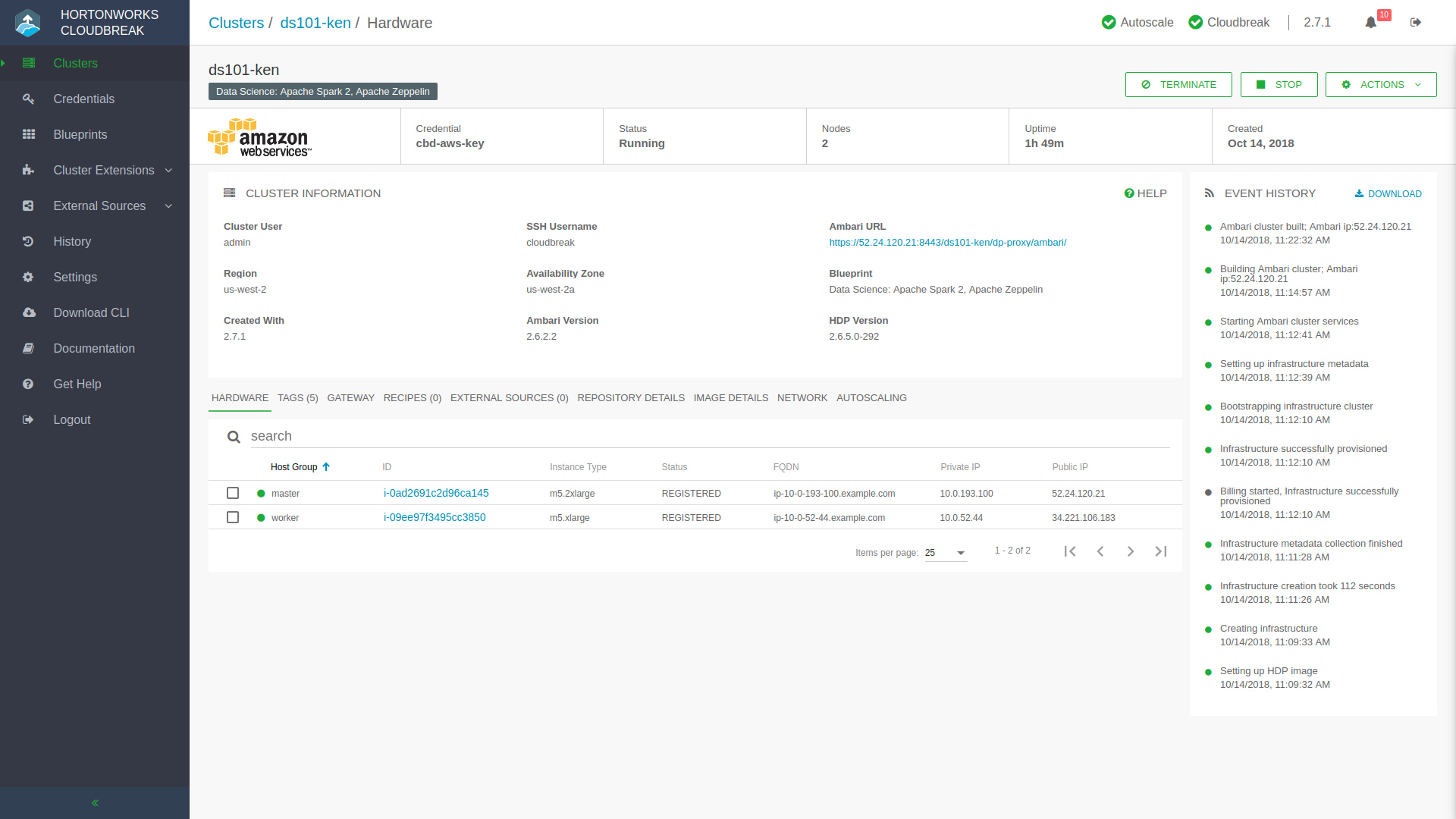
Anywho, go ahead and click that big green Create Cluster button and you’ll start to see notifications streaming in as Hortonworks Cloudbreak progresses through the stages of deployment. You’ll be returned to the main Hortonworks Cloudbreak dashboard where you’ll see your new cluster represented. If you click into it you can watch the progress and find extra functions and metrics regarding this new cluster of yours.
Next Steps
Now that we’ve got Hortonworks Cloudbreak running the possibilities are endless. We could do side-by-side testing of variable clusters to decide which performs best, or to assess the performance/price of the various public cloud offerings. Move from large Data at Rest workloads in an HDP cluster right into a Hortonworks Data Flow cluster and start streaming data with Nifi. Run multiple workload quickly within a few quicks with Hortonworks Cloudbreak. It really helps get the juices flowing and gives you almost limitless sandboxes and pails to use in your Data Science and Data Analytic workloads.